
- Программно-аппаратная среда платформы HybriLIT
- Очереди
- Системы хранения и обработки данных на платформе
- Основные шаги для проведения расчетов на платформе
- Начало работы: удаленный вход на платформу
- Пакет Lmod
- Основные команды Linux
- Планировщик задач SLURM
- Компиляция и запуск
OpenMP-приложений
MPI-приложений
CUDA-приложений
Гибридные приложения OpenMP+CUDA
Гибридные приложения MPI+CUDA
Гибридные приложения MPI+OpenMP
OpenCL-приложений
Программно-аппаратная среда платформы HybriLIT
Учебно-тестовый полигон построен на основе вычислительных узлов с многоядерными процессорами Intel и графическими ускорителями Nvidia (подробнее можно посмотреть в разделе «Аппаратное обеспечение»).
Типы вычислительных узлов:
- CPU: узлы с многоядерными процессорами Intel Xeon Phi 7290
- CPU: узлы с многоядерными процессорами Intel Xeon E5-2695 v2
- GPU: узлы с многоядерными процессорами Intel Xeon E5-2695 v3 и графическими ускорителями Nvidia K80
- GPU: узлы с многоядерными процессорами Intel Xeon E5-2698 v4 и графическими ускорителями Nvidia V100

Очереди
Запуск задачи осуществляется с помощью постановки ее в очередь на счет. Так как HybriLIT является гетерогенной платформой, то для использования различных ресурсов были созданы отдельные очереди.
На текущий момент HybriLIT содержит 5 очередей:
- interactive* — включает 1 вычислительный узел с 2 Intel Xeon E5-2695 v2 12-cores (* означает, что очередь используется по умолчанию). Очередь подойдет для запуска тестовых программ. Время расчетов для этой очереди ограничено и составляет 2 часа;
- cpu — включает 15 вычислительных узла с 1 Intel Xeon Phi 72-cores на каждом. Очередь подойдет для запуска приложений, использующих центральные процессоры для расчетов. Время расчетов для этой очереди составляет до 7 дней;
- long — очередь включает 6 вычислительных узлов с 1 Intel Xeon Phi 72-cores на каждом. Очередь подойдет для запуска приложений, требующих длительных (до 4 недель) вычислений;
- gpu_k80 — очередь включает 1 вычислительный узел: 2 Intel Xeon E5-2695 v3 14-cores и 2 NVIDIA Tesla K80. Очередь подойдет для запуска приложений, использующих графические ускорители для расчетов. Время расчетов до 7 дней;
- gpu_volta — очередь включает 1 вычислительный узел: 2 Intel Xeon E5-2698 v4 20-cores и 8 NVIDIA V100. Очередь подойдет для запуска приложений, требующих длительных (до 7 дней) вычислений;
Гетерогенная платформа находится под управлением операционной системы AlmaLinux 9.6, с планировщиком задач SLURM и установленным программным обеспечением: компиляторами и пакетами для разработки, отладки и профилировки параллельных приложений, а также пакетом Lmod.
Системы хранения и обработки данных на платформе
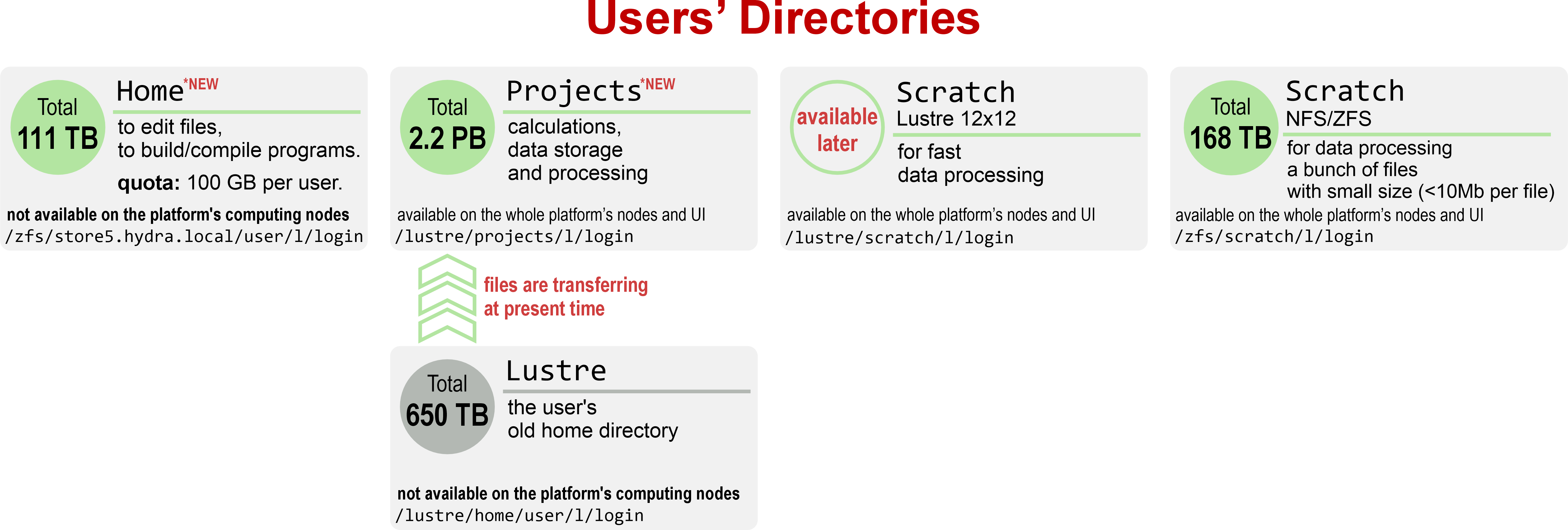
Для повышения надежности и скорости работы всей Платформы введены различные системы хранения и обработки данных пользователей:
-
Home
Домашняя директория пользователя: /zfs/store5.hydra.local/user/l/login
Директория предназначена для редактирования файлов, сборки и компиляции программ. На эту директорию установлена квота в 100 GB на каждого пользователя.
Домашняя директория не предназначена для проведения расчетов и не доступна на вычислительных узлах платформы! -
Project
Директория пользователя для проведения расчетов, хранения и обработки данных: /lustre/projects/l/login
Директория предназначена для проведения расчетов и размещения рабочих файлов (исполняемых, входных и выходных файлов) при выполнении счетных задач на платформе. На данную директорию не установлена квота и она доступна на вычислительных узлах платформы. -
Scratch Lustre 12×12*
Директория пользователя для быстрой обработки данных: /lustre/scratch/l/login (* будет доступна позже)
Директория размещена на файловой системе Lustre 12×12, имеющей специальную архитектуру, оптимизированную для операций ввода-вывода данных. Директория предназначена для обработки массивно-параллельных задач, использующих интенсивный ввод-вывод данных.
В директории Scratch 12×12 не гарантируется сохранение файлов, дата размещения которых более 90 дней. -
Scratch NFS/ZFS
Резервная директория пользователя для обработки данных: /zfs/scratch/l/login
Директория размещена на файловой системе NFS/ZFS и предназначена для запуска задач, связанных с обработкой большого количества файлов небольшого размера (менее 10 Mb).
В директории Scratch NFS/ZFS не гарантируется сохранение файлов, дата размещения которых более 90 дней. -
Lustre
Старая домашняя директория пользователя: /lustre/home/user/l/login.
В настоящее время продолжается копирование файлов из предыдущего хранилища в текущую директорию пользователя /lustre/projects.
Этот процесс может занять некоторое время. Просим не беспокоиться — все данные сохранены и будут полностью перенесены.
Основные шаги для проведения расчетов на платформе

Начало работы: удаленный вход на платформу
Удаленный доступ к гетерогенной вычислительной платформе HybriLIT открыт только по протоколу SSH.
DNS адрес гетерогенной платформы:hydra.jinr.ru
Более подробная инструкция для подключения к платформе для различных операционных систем приведена ниже.
Для пользователей OS Linux
Запустите терминал и введите:
|
1 |
$ ssh USERNAME@hydra.jinr.ru |
где USERNAME – логин, который Вы получили при регистрации, hydra.jinr.ru – адрес сервера. После требования системы ввести пароль — введите его. В случае успешной авторизации на платформе Вы увидите командную строчку на экране:
|
1 |
[USERNAME@hydra ~] $ |
Это означает, что Вы подключились к платформе и находитесь в своем домашнем каталоге.
![]() При первой попытке доступа появится уведомление о незнакомом IP-адресе, к которому Вы пытаетесь подключиться. Наберите
yes, нажмите Enter, и этот адрес будет добавлен в список известных адресов.
При первой попытке доступа появится уведомление о незнакомом IP-адресе, к которому Вы пытаетесь подключиться. Наберите
yes, нажмите Enter, и этот адрес будет добавлен в список известных адресов.
Для пользователей OS Windows
Для подключения к платформе пользователей Windows необходимо использовать специальную программу – SSH-клиент, например, PuTTY или MobaXterm.
Установка для программы PuTTY не требуется. Нужно просто скачать файл putty.exe по ссылке http://the.earth.li/~sgtatham/putty/latest/x86/putty.exe в удобное место на компьютере и запустить его.
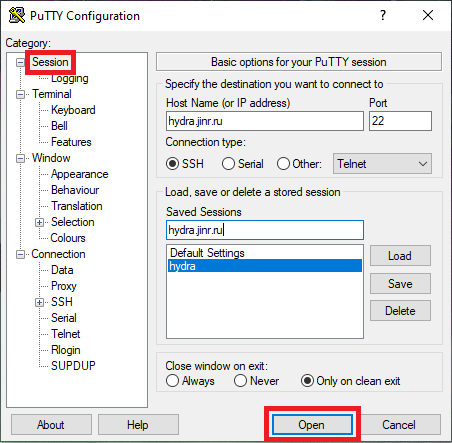
Ниже описана пошаговая процедура настройки PuTTY для доступа к платформе.
- В поле Host Name (or IP address) введите адрес сервера: hydra.jinr.ru
- В поле Saved Sessions введите предпочтительное имя для текущего подключения (например, hydra.jinr.ru).
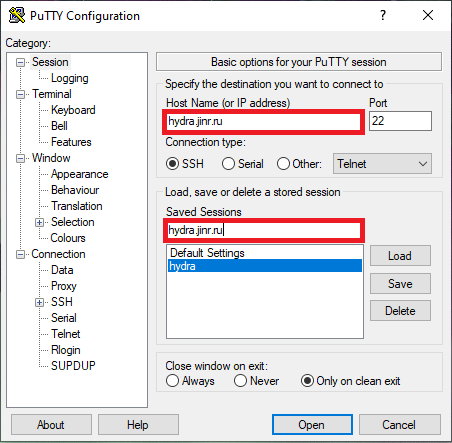
- Для подключения удаленного графического интерфейса X11 переходим на вкладку Connection SSH>X11 и выделяем поле Enable X11 forwarding
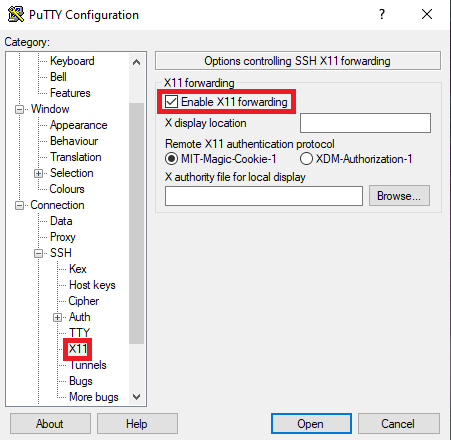
- Проверяем, что на вкладке Connection > SSH > Tunnels выделено поле Local ports accept connections from other hosts
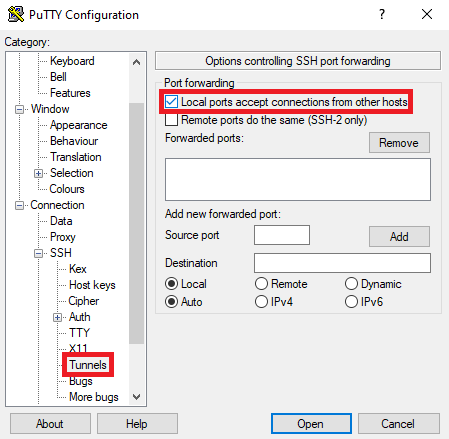
- После этого возвращаемся во вкладку Session и нажимаем Save, чтобы сохранить все наши изменения.
- Нажимаем Open для подключения к платформе HybriLIT и вводим логин и пароль, которые Вы получили при регистрации.
В случае успешной авторизации на платформе Вы увидите командную строчку на экране:
|
1 |
[USERNAME@hydra ~] $ |
Это означает, что Вы подключились к платформе и находитесь в своем домашнем каталоге.
![]() При первой попытке доступа появится уведомление о незнакомом IP-адресе, к которому Вы пытаетесь подключиться. Наберите
yes , нажмите Enter, и этот адрес будет добавлен в список известных адресов.
При первой попытке доступа появится уведомление о незнакомом IP-адресе, к которому Вы пытаетесь подключиться. Наберите
yes , нажмите Enter, и этот адрес будет добавлен в список известных адресов.
Инструкция по установке MobaXterm
1. По ссылке mobaxterm.mobatek.net можно на выбор скачать портативную версию программы, не требующую установки (синяя кнопка), и версию с установщиком. Далее рассмотрим версию с установкой.
2. После скачивания установщика на компьютер, открыть файл MobaXterm_Setup_XX.exe и следовать стандартным шагам установки программы.
3. По завершению установки на рабочем столе появится ярлык для запуска программы.
4. Запустите ее и в верхнем меню в разделе Sessions выберите New session
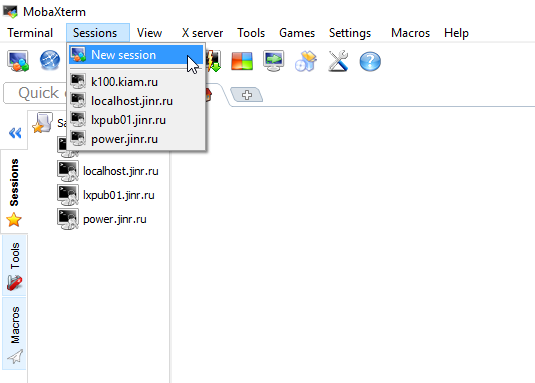
5. Введите в поле Remote host адрес сервера hydra.jinr.ru и нажмите OK
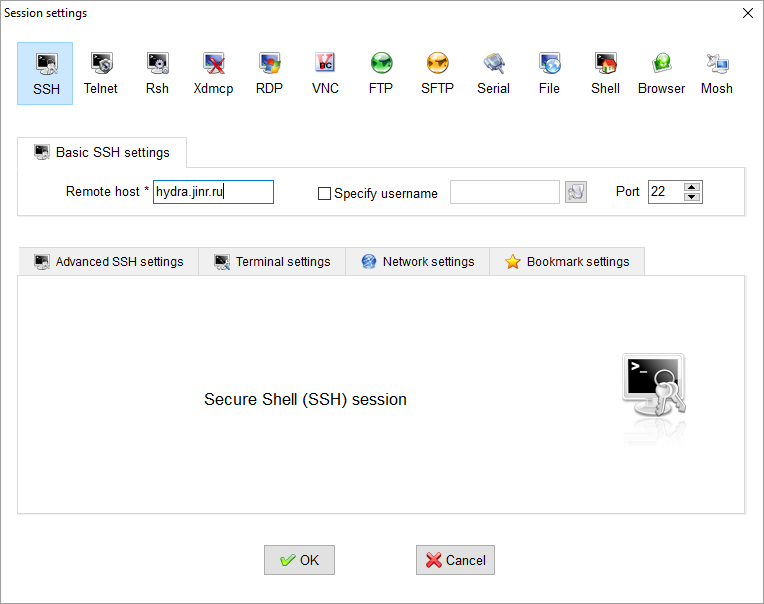
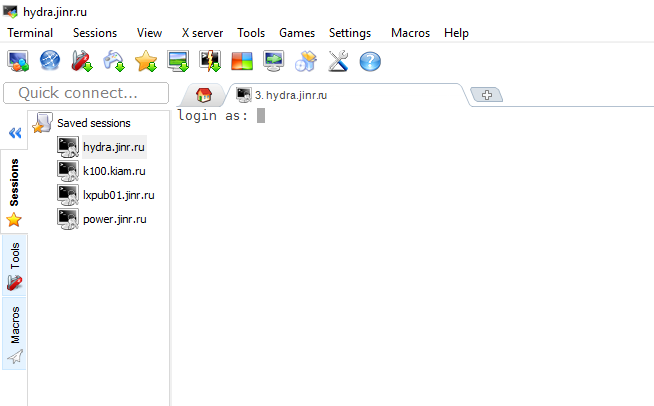
6. Откроется новая вкладка, где Вам надо будет ввести логин и пароль для доступа на платформу. И в случае успешной авторизации на платформе Вы увидите командную строчку на экране:
[USERNAME@hydra ~] $
Пакет Lmod
Для динамического изменения переменных окружения на платформе установлен пакет Lmod 9.1.2. Данный пакет позволяет пользователю изменять список компиляторов для сборки приложений с поддержкой основных языков программирования (C/C++, FORTRAN, Java), технологий параллельного программирования (OpenMP, MPI, OpenCL, CUDA) и использовать установленные на платформе пакеты программ. Перед компиляцией приложения пользователю необходимо загрузить модули, необходимые для работы.
Основные команды для работы с модулями:
|
1 2 3 4 5 |
module avail - просмотреть список активных модулей; module add [ИМЯ_МОДУЛЯ] - добавить модуль в список подключенных; module list - просмотреть список подключенных модулей; module rm [ИМЯ_МОДУЛЯ] - выгрузить модуль из списка подключенных; module show [ИМЯ_МОДУЛЯ] - описание изменений, вносимых модулем. |
![]() Загруженные модули не сохраняются между сессиями, если Вам нужно всегда использовать один набор модулей, допишите команду:
Загруженные модули не сохраняются между сессиями, если Вам нужно всегда использовать один набор модулей, допишите команду:
|
1 |
module add [ИМЯ_МОДУЛЯ] в файл ~/.bashrc. |
Также Вы можете подключить версии компиляторов и пакеты, которые установлены в системе cvmfs (CernVM File System).
CernVM File System
Добавление системы CernVM-FS к установленному списку программных пакетов позволяет получить доступ к установленному программному обеспечению CERN.
Список доступных пакетов можно посмотреть, выполнив команду:
|
1 |
ls /cvmfs/sft.cern.ch/lcg/releases |
Стоит отметить, что директория /cvmfs/sft.cern.ch/ монтируется динамически при обращении к ее содержимому и спустя некоторое время бездействия может исчезнуть из списка доступных директорий. Заново смонтировать ее можно, повторно выполнив команду
|
1 |
ls /cvmfs/sft.cern.ch/lcg/releases |
Для использования компиляторов и программных пакетов необходимо выполнить команду:
|
1 |
source [ПУТЬ_ДО_ФАЙЛА_С_ПЕРЕМЕННЫМИ_ОКРУЖЕНИЯ] |
Основные команды Linux
| Команда | Описание |
|---|---|
| man <имя_команды> | после вводе этой команды на экране появляется информация о команде |
| man -k <ключевое_слово> | получить список команд, к которым относится данное <ключевое слово> |
| Простейшие действия: | |
| ls | получить список файлов в текущем каталоге |
| ls -la | получить подробный список, включая скрытые файлы |
| cd <каталог> | сменить текущий каталог. Если имя каталога не указывается, то текущим становится домашний каталог пользователя |
| cp <что_копировать> <куда_копировать> | копировать файлы |
| mv <что_перемещать> <куда_перемещать> | переместить или переименовать файл |
| ln -s <на_что_сделать_ссылку> <имя_ссылки> | создать символьную ссылку |
| rm <файл(ы)> | удалить файл(ы) |
| rm -r <директория> | удалить директорию, с параметром <-r> — рекурсивно |
| cat <имя_файла> | вывод содержимого файла на стандартный вывод (по умолчанию — на экран) |
| more <имя_файла> | вывод содержимого файла на стандартный вывод (по умолчанию — на экран) |
| less <имя_файла> | просмотр содержимого текстового файла с возможностью вернуться к предыдущим страницам. Нажатие q означает выход из программы |
| find <каталог> -name <имя_файла> | найти файл <имя_файла> в <каталоге> и отобразить результат на экране |
| tar -zxvf <файл> | распаковать архив tgz или tar.gz |
| nano <имя_файла> | редактировать текстовый файл с помощью текстового редактора nano |
| vim <имя_файла> | редактировать текстовый файл с помощью текстового редактора vim |
| pico <имя_файла> | редактировать текстовый файл с помощью текстового редактора pico |
| mc | запустить программу управления файлами MidnightCommander |
| manmc | вывести описание опций MidnightCommander |
| Стандартные команды: | |
| pwd | вывести имя текущего каталога |
| whoami | вывести имя, под которым Вы зарегистрированы |
| date | вывести текущие дату и время |
| time <имя программы> | выполнить программу и получить информацию о времени, нужном для ее выполнения |
| ps -a | вывести список текущих процессов в текущем сеансе работы |
| chmod <права доступа><файл> | изменить права доступа к файлу, владельцем которого Вы являетесь |
| *Есть три способа доступа к файлу: | |
| -чтение | —read |
| -запись | — write |
| -исполнение | — execute |
| Отсутствие права доступа показывается как | «-« |
| и три типа пользователей: | |
| — владелец файла | (u) |
| — члены группы владельца | (g) |
| — все остальные | (o) |
| Пример: | |
| chmod a+r zara | Эта команда позволит Вам установить права доступа на чтение для файла zara для всех (all=user+group+others) |
| chmod o-x zara | Эта команда отнимет право доступа на исполнение файла у всех, кроме пользователя и группы |
| chown <новый_владелец> <файлы> | изменить владельца файлов |
| chgrp <новая_группа> <файлы> | изменить группу принадлежности для файлов |
| ls -l <имя_файла> | проверить текущие права доступа *если файл доступен всем пользователям, то напротив имени файла будет следующая комбинация букв: rwxrwxrwx |
| Контроль процессов: | |
| <имя_файла> | grep < фрагмент> | поиск <фрагмента> текста в файле <имя_файла> |
| man grep | справка о команде |
| ps axu | grep <Ваше_имя_пользователя> | отобразить все процессы, запущенные в системе от Вашего_имени_пользователя |
| kill <номер процесса> | принудительно завершить («убить») процесс с заданным номером |
| killall <имя_программы> | «убить» все процессы по имени программы |
Планировщик задач SLURM
SLURM – это высоко масштабируемый отказоустойчивый менеджер кластеров и планировщик заданий с открытым кодом, который обеспечивает три основные функции:
- Выделяет эксклюзивный и/или неэксклюзивный доступ к ресурсам (компьютерные узлы) для пользователей в течение некоторого периода времени;
- Обеспечивает основу для запуска, работы и мониторинга работы (как правило, параллельной работе) на множестве выделенных узлов;
- Поддерживает очередь ожидающих заданий и управляет общей загрузкой ресурсов в процессе выполнения работы.
1. Основные команды
К основным командам планировщика SLURM относятся: sbatch, scancel, sinfo, squeue, scontrol.
- sbatch — команда для запуска приложения в режиме очереди
После запуска приложению присваивается персональный номер jobid, по которому его можно найти в списке запущенных приложений (squeue). Результат записывается в файл с именем slurm-jobid.out.
Пример использования sbatch:
|
1 2 |
[user@hydra] sbatch runscript.sh Submitted batch job 141980 |
- squeue — команда для просмотра списка запущенных приложений в очереди;
Одним из основных параметров списка является состояние приложений. Запущенное приложение может иметь одно из следующих состояний:
- RUNNING (R) – выполняется;
- PENDING (PD) – в очереди;
- COMPLETING (CG) – завершается. (в этом состоянии, возможно, может понадобиться помощь системного администратора для удаления приложения из очереди).
Пример использования squeue:
|
1 2 3 4 |
[user@hydra] squeue JOBID PARTITION NAME USER ST TIME NODES NODELIST 28727 cpu sb_12945 dmridu R 8-00:12:12 1 n01p001 29512 gpu_k80 smd5a ygorshko R 2-04:13:11 1 blade09 |
- sinfo — команда для просмотра состояния вычислительных узлов и очередей. Вычислительные узлы могут быть в одном из следующих состояний:
- idle – узел свободен;
- alloc – узел используется процессом;
- mix – узел частично занят, частично свободен;
- down, drain, drng – узел заблокирован.
Пример использования sinfo:
|
1 2 3 4 5 6 7 8 9 |
[user@hydra] sinfo PARTITION AVAIL TIMELIMIT NODES STATE NODELIST interactive* up 1-00:00:00 1 idle blade09 interactive up 30-00:00:0 1 idle blade09 cpu up 30-00:00:0 1 inval n01p001 cpu up 30-00:00:0 14 idle n01p[002-015] long up 30-00:00:0 6 idle n01p[016-021] gpu_k80 up 30-00:00:0 1 idle blade09 gpu_volta up 30-00:00:0 1 idle blade09 |
- scancel — команда для удаления приложения из очереди.
Пример использования scancel для удаления из очереди приложения с jobid 141980:
|
1 |
[user@hydra] scancel 141980 |
- scontrol — используется для просмотра или изменения состояния SLURM, включающего: задачи, узла и очереди. Многие из управляющих команд могут выполняться только суперпользователем.
Пример использования scontrol для просмотра характеристик запущенного приложения:
|
1 2 3 4 |
[user@hydra] scontrol show job 141980 JobId=141980 JobName=test UserId=user(11111) GroupId=hybrilit(10001) JobState=RUNNING Reason=None Dependency=(null) |
Список характеристик содержит такие параметры, как:
| параметр | функция |
|---|---|
| UserId | имя пользователя |
| JobState | состояние приложения |
| RunTime | текущее время расчетов |
| Partition | используемая очередь |
| NodeList | используемые узлы |
| NumNodes | число используемых узлов |
| NumCPUs | число используемых ядер процессора |
| Gres | число используемых графических ускорителей или сопроцессоров |
| MinMemoryCPU | количество используемой оперативной памяти |
| Command | расположение файла для запуска приложения |
| StdErr | расположение файла с ошибками |
| StdOut | расположение файла с выходными данными |
Пример использования scontrol для просмотра характеристик узлов:
|
1 2 |
[user@hydra] scontrol show nodes [user@hydra] scontrol show node blade09 |
Список характеристик содержит такие параметры, как:
NodeName – hostname вычислительного узла;
CPUAlloc – количество загруженных вычислительных ядер;
CPUTot – общее число вычислительных ядер на узле;
CPULoad – загрузка вычислительных ядер;
Gres – число доступных для расчетов графических уcкорителей и сопроцессоров;
RealMemory – общее количество оперативной памяти на узле;
AllocMem – количество загруженной оперативной памяти;
State – состояние узла.
2. Очереди
Запуск задачи осуществляется с помощью постановки ее в очередь на счет. Так как HybriLIT является гетерогенной платформой, то для использования различных ресурсов были созданы отдельные очереди.
На текущий момент HybriLIT содержит 5 очередей:
- interactive* — включает 1 вычислительный узел с 2 Intel Xeon E5-2695 v2 12-cores (* означает, что очередь используется по умолчанию). Очередь подойдет для запуска тестовых программ. Время расчетов для этой очереди ограничено и составляет 2 часа;
- cpu — включает 15 вычислительных узла с 1 Intel Xeon Phi 72-cores на каждом. Очередь подойдет для запуска приложений, использующих центральные процессоры для расчетов. Время расчетов для этой очереди составляет до 7 дней;
- long — очередь включает 6 вычислительных узлов с 1 Intel Xeon Phi 72-cores на каждом. Очередь подойдет для запуска приложений, требующих длительных (до 4 недель) вычислений;
- gpu_k80 — очередь включает 1 вычислительный узел: 2 Intel Xeon E5-2695 v3 14-cores и 2 NVIDIA Tesla K80. Очередь подойдет для запуска приложений, использующих графические ускорители для расчетов. Время расчетов до 7 дней;
- gpu_volta — очередь включает 1 вычислительный узел: 2 Intel Xeon E5-2698 v4 20-cores и 8 NVIDIA V100. Очередь подойдет для запуска приложений, требующих длительных (до 7 дней) вычислений;
3. Описание и примеры script-файлов
Для запуска приложения с помощью команды sbatch требуется использовать script-файл. В общем случае, script-файл – это обычный bash файл, удовлетворяющий следующим правилам:
![]()
- Первая строка содержит #!/bin/sh (или #!/bin/bash) , что позволяет скрипту быть запущенным как bash-script;
- Строки, начинающиеся с # — это комментарии;
- строки, начинающиеся с #SBATCH , устанавливают параметры для планировщика SLURM;
- Все параметры планировщика SLURM должны быть установлены до непосредственного запуска приложения;
- Script-файл содержит команду для запуска приложений.
SLURM имеет большое количество различных параметров (https://computing.llnl.gov/linux/slurm/sbatch.html). Ниже приведены параметры обязательные или рекомендованные для использования на платформе HybriLIT:
- -p — используемая очередь. В случае отсутствия данного параметра задача будет поставлена в интерактивную очередь, время выполнения в которой ограничено 1 часом. В зависимости от типа используемых ресурсов приложение может быть запущено в одной из существующих очередей: cpu, phi, gpu, gpuK80;
- -n — число используемых процессов;
- -t — резервируемое время расчетов. Это обязательный параметр. Доступны следующие форматы: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds;
- --gres — число резервируемых графических ускорителей NVIDIA или сопроцессоров Intel Xeon Phi. Это обязательный параметр для задач, использующих gpu или сопроцессоры Intel Xeon Phi;
- --mem — резервируемая оперативная память, в мегабайтах. Это необязательный параметр, но если ваше приложение использует большое количество оперативной памяти, рекомендуется задать данный параметр;
- -N – число используемых узлов. Этот параметр следует устанавливать только в том случае, если количество ресурсов на 1 узле недостаточно для выполнения вашего расчета;
- -o – имя выходного файла. По умолчанию результат записывается в файл с именем slurm-jobid.out.
Ниже приведены примеры скриптов, использующие различные ресурсы платформы HybriLIT.
- Для расчетов на CPU:
|
1 2 3 4 |
#!/bin/sh #SBATCH -p cpu #SBATCH -t 60 ./a.out |
- Для расчетов с использованием GPU:
|
1 2 3 4 5 |
#!/bin/sh #SBATCH -p gpu_volta #SBATCH -t 60 #SBATCH -gres=gpu:2 ./a.out |
Примеры script-файлов для различных технологий программирования будут приведены ниже в соответствующих разделах.
Компиляция и запуск
OpenMP-приложений
УЧЕБНОЕ ПОСОБИЕ «Основы технологии OpenMP на кластере HybriLIT».
OpenMP (Open Multi-Processing) — открытый стандарт для разработки многопоточных программ на языках С, С++ и Fortran. Содержит набор директив компилятора, библиотечных процедур и переменных окружения, которые предназначены для разработки многопоточных приложений на многопроцессорных системах с общей памятью. Программная модель — Fork-Join Model, которая заключается в следующем (Рис.1.):
- Любая программа начинает работу в нулевом потоке (Master thread), далее нулевой поток создает (с помощью директив компилятора) группу потоков — FORK, которые выполняются параллельно, затем, по завершении работы порожденных потоков в параллельной области, происходит синхронизация — JOIN, и программа продолжает работу в основном потоке.

Рис.1. Программная модель Fork-Join.
Компиляция
Используются стандартные компиляторы с ключами поддержки OpenMP. Доступны компиляторы GNU и Intel. Доступны компиляторы GNU версии 12.3.0 и 13.1.0 с поддержкой OpenMP.
Перед компиляцией с использованием Intel — компиляторов необходимо загрузить соответствующий модуль:
|
1 |
$ module add intel/v2025.3.1 |
На данный момент доступны 2 версии компилятора Intel: v2023.1.0 (используются компиляторы Intel Compile Classic: icc, icpc) и v2025.3.1 (используются оптимизированные компиляторы: icx, icpx). Ниже представлены команды для компиляции программ, написанных на С, С++ или Fortran для различных компиляторов:
| Intel 2023 | Intel 2025 | GNU | |
|---|---|---|---|
| C | icc -qopenmp hello.c | icx -qopenmp hello.c | gcc -fopenmp hello.c |
| C++ | icpc -qopenmp hello.cpp | icpx -qopenmp hello.cpp | g++ -fopenmp hello.cpp |
| Fortran | ifort -qopenmp hello.f | ifx -qopenmp hello.f | gfortran -fopenmp hello.f |
|
1 |
$ icx -qopenmp hello.c -o hello |
имя бинарного файла будет hello, а на языке Fortran:
|
1 |
$ ifx -qopenmp hello.f -o hello |
Запуск
Запуск OpenMP-приложений осуществляться с помощью script-файла, содержащего следующую информацию:
|
1 2 3 4 5 |
#!/bin/sh # используемый shell #SBATCH -p cpu # выбор типа используемой очереди #SBATCH -c 5 # установка числа вычислительных потоков #SBATCH -t 60 # установка времени расчета ./test # запуск приложения |
Использование следующей установки оптимизирует распределение потоков по вычислительным ядрам и, как правило, обеспечивает меньшее время счета по сравнению с расчетом без использования этой команды.
|
1 |
$ export OMP_PLACES=cores |
Число OMP-нитей (потоков) может быть задано с помощью переменной окружения OMP_NUM_THREADS до выполнения программы в командной строке:
|
1 |
$ export OMP_NUM_THREADS=threads |
где threads — количество OMP-нитей.
Таким образом, рекомендуемый script-файл для OpenMP-приложений, например, с 5-ю потоками имеет вид:
|
1 2 3 4 5 6 7 |
#!/bin/sh #SBATCH -p cpu #SBATCH -c 5 #SBATCH -t 60 export OMP_NUM_THREADS=5 export OMP_PLACES=cores ./a.out |
Для запуска приложения используется следующая команда:
|
1 |
$ sbatch omp_script |
Компиляция и запуск MPI-приложений
Message Passing Interface (MPI, интерфейс для передачи сообщений) — программный интерфейс (API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу.
Для работы с MPI доступны компиляторы GNU и Intel.
*Опубликовано учебное пособие Практическое введение в технологию MPI на платформе HybriLIT (скачать файл).
Компиляторы GNU
MPI-программы могут компилироваться GNU-компиляторами с библиотекой OpenMPI. GNU-компиляторы устанавливаются на HybriLIT по умолчанию. Для доступа к OpenMPI-библиотекам нужно добавить подходящий модуль 5.0.9:
|
1 |
$ module add openmpi/v5.0.9_gcc1230 |
Компиляция
Ниже представлены команды для компиляции программ, написанных на С, С++ или Fortran для GNU-компилятора:
| Язык программирования | Команды вызова компилятора |
|---|---|
| C | mpicc |
| C++ | mpiCC / mpic++ / mpicxx |
| Fortran 77 | mpif77 / mpifort (*) |
| Fortran 90 | mpif90 / mpifort (*) |
![]() (*) Рекомендуется использовать команду mpifort вместо mpif77 или mpif90, которые считаются устаревшими. С помощью mpifort можно компилировать любые Fortran-программы, использующие в качестве интерфейса «
mpif.h » или «
use mpi «.
(*) Рекомендуется использовать команду mpifort вместо mpif77 или mpif90, которые считаются устаревшими. С помощью mpifort можно компилировать любые Fortran-программы, использующие в качестве интерфейса «
mpif.h » или «
use mpi «.
Пример компиляции программы на языке С:
|
1 |
$ mpicc example.c |
Если не задавать имя исполняемого файла, получаемого после успешной компиляции, ему по умолчанию присваивается имя a.out .
Для запуска программы с использованием модулей OpenMPI используется script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#!/bin/sh # Пример скрипта для использования OpenMPI: # Выбор очереди, в которую будет отправлена задача #SBATCH -p cpu # Запуск MPI задачи на 2 узла, по 3 MPI-процесса на узел #SBATCH --nodes=2 # Количество узлов #SBATCH --ntasks-per-node=3 # количество MPI-процессов на узел # # Установка времени работы программы в формате: # минуты # минуты:секунды # дни-часы # дни-часы:минуты:секунды #SBATCH -t 60 # время выполнения программы в минутах # # запуск программы на счет: mpirun ./a.out |
Intel-компилятор
Для использования MPI с Intel-компилятором нужно добавить модуль intel/v2023.1.0:
|
1 |
$ module add intel/v2023.1.0 |
или intel/v2025.3.1
|
1 |
$ module add intel/v2025.3.1 |
MPI-библиотека входит в состав этого модуля.
Компиляция
Ниже представлены команды для компиляции программ, написанных на С, С++ или Fortran для Intel-компилятора:
| Язык программирования | Команды вызова компилятора intel/v2023.1.0 | Команды вызова компилятора intel/v2025.3.1 |
|---|---|---|
| C | mpiicc | mpiicx |
| C++ | mpiicpc | mpiicpx |
| Fortran | mpiifort | mpiifort |
Пример компиляции программы на языке Fortran:
|
1 |
$ mpiifort example.f |
![]() Опции оптимизации компиляторов:
Опции оптимизации компиляторов:
| Опция | Назначение |
|---|---|
| -O0 | без оптимизации; используется по умолчанию для GNU-компилятора |
| -O2 | используется по умолчанию для Intel-компилятора |
| -O3 | может быть эффективна для определенного класса программ |
| -march=native -march=core2 | настройка на архитектуру процессоров (использование дополнительных возможностей процессоров Intel) |
Запуск задачи на счет
В счетном режиме запуск задачи на счет осуществляется планировщиком SLURM командой:
|
1 |
$ sbatch script_mpi |
где script_mpi – имя заранее заготовленного script-файла, содержащего «паспорт задачи».
Пример script-файла для запуска MPI-приложений на двух вычислительных узлах
Далее приведены два способа распределения MPI процессов по вычислительным узлам.
Пример использования комбинации ключей --tasks-per-node и -n : задается 10 процессов ( -n 10 ) по 5 процессов на один вычислительный узел ( --tasks-per-node=5). Таким образом, вычислительная работа распределяется по 2 вычислительным узлам:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#!/bin/sh #задание входной очереди задач для MPI-программ: #SBATCH -p cpu #выделение нужного числа процессоров (ядер), #равного числу параллельных процессов: #SBATCH -n 10 #задание количества процессов на узел: #SBATCH --tasks-per-node=5 #установка ограничения на время выполнения расчета: #Доступны следующие форматы: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 #задание своего имени файла для листинга задачи: #SBATCH -o output.txt #запуск на счет: mpirun ./a.out |
Пример использования комбинации ключей --tasks-per-node и -N: задается по 5 процессов на один вычислительный узел ( --tasks-per-node=5 ) и количество узлов ( -N 2 ). Таким образом, создается 10 процессов и вычислительная работа распределяется по 2 узлам:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#!/bin/sh #задание входной очереди задач для MPI-программ: #SBATCH -p cpu #выделение нужного числа процессоров (ядер), #равного числу параллельных процессов на узел: #SBATCH --tasks-per-node=5 #запуск процессов на 2 вычислительных узлах (**): #SBATCH -N 2 #установка ограничения на время выполнения расчета: #Доступны следующие форматы: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 #задание своего имени файла для output-файла: #SBATCH -o output.txt #запуск на счет: mpirun ./a.out |
![]() Дополнительные узлы (**) имеет смысл заказывать, если для решения задачи требуется большое число параллельных процессов (больше 24).
Дополнительные узлы (**) имеет смысл заказывать, если для решения задачи требуется большое число параллельных процессов (больше 24).
Пример простейшего script-файла, в котором из множества возможных SLURM-директив фигурируют только самые необходимые:
|
1 2 3 4 5 |
#!/bin/sh #SBATCH -p cpu #SBATCH -n 7 #SBATCH -t 60 mpirun ./a.out |
Здесь исполняемый файл a.out, изготовленный компилятором, отправляется во входную очередь задач, предназначенных для счета на cpu-подмножестве платформы HybriLIT. Задача требует 7 ядер. Задача получит уникальный номер во входной очереди. Пусть это будет 1234. Тогда листинг задачи будет оформлен как файл slurm-1234.out в той же директории, где находился ее исполняемый файл a.out.
![]()
В программе на языке Fortan для подключения MPI-процедур обычно используется оператор Include ‘mpif.h’ , который можно заменить на более функциональный вариант – модуль mpi.mod, подключаемый командой Use mpi.
![]()
При запуске задачи на счет
- необходимо учитывать существующие ограничения по ресурсам на платформе;
- желательно использовать тот модуль установки переменных окружения, с которым программа была откомпилирована;
- пока задача не досчиталась до конца, нельзя удалять исполняемый файл и менять входные данные.
Компиляция и запуск CUDA-приложений
CUDA (Compute Unified Device Architecture) — программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы NVIDIA (GPU).
Доступные версии CUDA
Наиболее эффективной технологией, позволяющей использовать графические процессоры NVIDIA, является платформа параллельных вычислений Compute Unified Device Architecture (CUDA), обеспечивающая набор расширений для языков C/С++ , Fortran.
Для разработки параллельных приложений (отладки, профилирования и компиляции), использующих графические ускорители NVIDIA на платформе HybriLIT доступен компилятор nvcc из NVIDAI CUDA Toolkit.
Компиляция CUDA C/C++ приложений
На платформе доступны следующие версии CUDA, подключаемые через соответствующие модули пакета Lmod:
| Версия CUDA | Подключаемый модуль |
|---|---|
| 11.4 | $ module add cuda/v11.4 |
| 13.0 | $ module add cuda/v13.0 |
Для проведения расчетов с использованием графических ускорителей доступны два представителя семейства графических ускорителей NVIDIA Tesla K80 и NVIDIA Tesla V100. Согласно принятой NVIDIA системе наименования архитектур, графические процессоры именуют как sm_xy , где х обозначает число GPU-поколения, у — версии в этом поколении. Графические процессоры Tesla K80 — sm_37 , Tesla V100 — sm_70 .
CUDA 11.4, 13.0
Для компиляции CUDA-приложений, поддерживающей все имеющиеся на платформе архитектуры, можно использовать одну команду для компиляции:
|
1 |
$ nvcc app.cu --gpu-architecture=compute_35 --gpu-code=sm_37,sm_70 |
Компиляция приложений с использованием библиотек CUDA
Для проведения расчетов на графических ускорителях программно-аппаратная платформа CUDA предоставляет ряд хорошо оптимизированных математических библиотек, не требующих специальной установки. Например:
- библиотека для матрично-векторных операций cuBLAS – реализация библиотеки BLAS (Basic Linear Algebra Subprograms);
- библиотека CUFFT, реализация быстрого преобразования Фурье (FFT), которая состоит из двух отдельных библиотек: CUFFT и cuFFTW;
- библиотека cuRAND, предоставляющая средства для эффективной генерации высококачественных псевдослучайных и квазислучайных чисел;
- библиотека cuSPARSE, предназначенная для операций с разряженными матрицами, например, для решения систем линейных алгебраических уравнений с матрицей системы, имеющей ленточную структуру.
Более подробная информация доступна по ссылке: http://docs.nvidia.com/cuda/
![]()
Ниже представлен пример компиляции приложений с функциями из библиотеки cuBLAS и cuFFT:
|
1 |
$ nvcc app.cu -lcublas -lcufft --gpu-architecture=compute_35 --gpu-code=sm_37 |
Как видно из этой строки компиляции, необходимо только добавить ключи -lcublas -lcufft.
Запуск GPU-приложений на платформе в системе SLURM
Для запуска приложений, использующих графические ускорители, в пакетном режиме в системе SLURM необходимо указать в запускаемом script-файле следующие обязательные параметры/опции:
- имя соответствующей очереди, в зависимости от типа GPU (см. очереди). Например, для использования в расчетах графических ускорителей NVIDIA Tesla K80 , в script-файл надо добавить строку:
|
1 |
#SBATCH -p gpu_K80 |
- количество требуемых графических процессоров (GPU), которое задается опцией
--gres (Generic сonsumable RESources) в виде:
|
1 |
--gres=gpu <кол-во GPU на одном узле> |
Например, для использования 3 GPU на одном узле, в script-файл надо добавить строку:
|
1 |
#SBATCH --gres=gpu:3 |
Для использования в расчетах большего количества GPU, чем на одном узле, в script-файл надо добавить две строки:
|
1 2 |
#SBATCH --nodes=2 #SBATCH --gres=gpu:3 |
В этом случае будет задействовано 2 вычислительных узла с 3 графическими процессорами на каждом, суммарно 6 GPU.
![]()
Особенности вычислений с использованием ускорителя NVIDIA K80.
Графический ускоритель Tesla K80 является двухпроцессорным устройством (два графических процессора в одном устройстве) и обладает почти в два раза более высокой производительностью и вдвое более широкой полосой пропускания памяти по сравнению с предшественником — Tesla K40.
Для задействования 2 процессоров ускорителя Tesla K80 в script-файле необходимо указать параметр --gres=gpu:2 .
Приложения, использующие один графический процессор
Ниже представлены общие script-файлы для запуска приложений с использованием графического ускорителя NVIDIA Tesla K40:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#!/bin/sh # Example for one-GPU applications # # Set the partition where the job will run: #SBATCH -p gpu # #Set the number of GPUs per node #SBATCH --gres=gpu:1 # # Set time of work: Avaliable following formats: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 # #Submit a job for execution: ./testK40 # # End of submit file |
и одного процессора ускорителя Tesla K80 в пакетном режиме в системе SLURM:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#!/bin/sh # Example for one-GPU applications # # Set the partition where the job will run: #SBATCH -p gpu_K80 # #Set the number of GPUs per node #SBATCH --gres=gpu:1 # # Set time of work: Avaliable following formats: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 # #Submit a job for execution: ./testK80 # # End of submit file |
Для использования в расчетах нескольких графических процессоров необходим механизм распределения задач между различными устройствами, в том числе находящимся на различных узлах платформы, т.е. возможны следующие случаи:
- несколько GPU на одном вычислительном узле;
- несколько вычислительных узлов с графическими процессорами.
Для эффективного использования нескольких графических ускорителей разрабатываются гибридные приложения, например, OpenMP+CUDA, MPI+CUDA, MPI+OpenMP+CUDA и т.п. Более подробную информацию можно найти в проекте GitLab “Parallel features”: https://gitlab-hybrilit.jinr.ru/
Компиляция и запуск гибридных приложений OpenMP+CUDA
В данном разделе представлен пример запуска приложения, использующего несколько графических процессоров (multi-GPU application) на одном узле. Например, такое приложение может быть написано с использованием двух технологий параллельного программирования OpenMP+CUDA, в котором каждому потоку/нити (OpenMP-thread) ставится в соответствие один графический процессор.
При использовании в расчетах ускорителей NVIDIA Tesla K40:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#!/bin/sh # Example for multi-GPU applications, # job running on a single node # # Set the partition where the job will run: #SBATCH -p gpu # #Set the number of GPUs per node # (maximum 3 ): #SBATCH --gres=gpu:3 # #Set number of cores per task #SBATCH -c 3 # # Set time of work: Avaliable following formats: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 # #Set OMP_NUM_THREADS to the same # value as -c if [ -n "$SLURM_CPUS_PER_TASK" ]; then omp_threads=$SLURM_CPUS_PER_TASK else omp_threads=1 fi export OMP_NUM_THREADS=$omp_threads # #Submit a job for execution: srun ./testK40 # # End of submit file |
При использовании в расчетах ускорителей NVIDIA Tesla K80:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
#!/bin/sh # Example for multi-GPU applications, # job running on a single node # # Set the partition where the job will run: #SBATCH -p gpu_K80 # #Set the number of GPUs per node # (maximum 4 - K80=2 x K40): #SBATCH --gres=gpu:4 # #Set number of cores per task #SBATCH -c 4 # # Set time of work: Avaliable following formats: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 # #Set OMP_NUM_THREADS to the same # value as -c if [ -n "$SLURM_CPUS_PER_TASK" ]; then omp_threads=$SLURM_CPUS_PER_TASK else omp_threads=1 fi export OMP_NUM_THREADS=$omp_threads # #Submit a job for execution: srun ./ testK80 # # End of submit file |
Компиляция и запуск гибридных приложений MPI+CUDA
В данном разделе представлен пример запуска приложения, использующего несколько графических процессоров (multi-GPU application) на нескольких вычислительных узлах. Например, такое приложение может быть написано с использованием двух технологий параллельного программирования MPI+CUDA, в котором каждому процессу ставится в соответствие один графический процессор, при этом явно указано количество процессов на узел.
При использовании в расчетах ускорителей NVIDIA Tesla K40:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#!/bin/sh # Example for GPU applications # # Set the partition where the job will run: #SBATCH -p gpu # # Set the number of nodes (maximum 4): #SBATCH --nodes=2 # #Specifies the number of GPU per node # (maximum 3 ): #SBATCH --gres=gpu:3 # # Set number of MPI tasks #SBATCH -n 6 # # Set time of work: Avaliable following formats: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 # #Submit a job for execution: mpirun ./testK40mpiCuda # # End of submit file |
При использовании в расчетах ускорителей NVIDIA Tesla K80:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#!/bin/sh # Example for GPU applications # # Set the partition where the job will run: #SBATCH -p gpu_K80 # # Set the number of nodes (maximum 2): #SBATCH --nodes=2 # #Specifies the number of GPU per node # (maximum 4 - K80=2 x K40): #SBATCH --gres=gpu:4 # # Set number of MPI tasks #SBATCH -n 8 # # Set time of work: Avaliable following formats: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 # #Submit a job for execution: mpirun ./testK80mpiCuda # # End of submit file |
Компиляция и запуск гибридных приложений MPI+OpenMP
Пожалуй, наиболее эффективным средством разработки гибридных алгоритмов является комбинация технологий MPI и OpenMP. Рассмотрим пример компиляции и запуска MPI+OpenMP программы на архитектуре KNL.
Для этого добавим mpi-модуль:
|
1 |
$ module add openmpi/v*.* |
или
|
1 |
$ module add intel/v*.* |
где *.* — номер версии.
Для компиляции можно воспользоваться компиляторами mpic++:
|
1 |
$ mpic++ HelloWorld_MpiOmp.cpp -fopenmp |
или mpiicpc:
|
1 |
$ mpiicpc HelloWorld_MpiOmp.cpp -fopenmp |
Запуск MPI+OpenMP-приложения на архитектуре KNL воспользоваться следующим скриптом:
|
1 2 3 4 5 6 7 |
#!/bin/sh #SBATCH -p cpu # Partition name #SBATCH --nodes=1 # Number of nodes #SBATCH --ntasks-per-node=2 # Number of tasks per node #SBATCH --cpus-per-task=3 # Number of OpenMP threads for each MPI process export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK mpirun ./a.out |
В SLURM-скрипте запрашивается запуск в очереди CPU на одном узле с двумя MPI-процессами и тремя OpenMP-нитями на каждый MPI-процесс.
После запуска приложения
|
1 |
$ sbatch script_knl.sh |
увидим следующее сообщение в выходном файле:
|
1 2 3 4 5 6 |
Hello from thread 1 out of 3 from process 0 out of 2 on CPU (node n01p005) Hello from thread 0 out of 3 from process 0 out of 2 on CPU (node n01p005) Hello from thread 2 out of 3 from process 0 out of 2 on CPU (node n01p005) Hello from thread 0 out of 3 from process 1 out of 2 on CPU (node n01p005) Hello from thread 1 out of 3 from process 1 out of 2 on CPU (node n01p005) Hello from thread 2 out of 3 from process 1 out of 2 on CPU (node n01p005) |
Скачать программу и ознакомиться с ней можно по адресу: disk.jinr.ru/mpiomp.
Компиляция и запуск OpenCL-приложений
Open Computing Language (OpenCL) — язык программирования высокого уровня, основанный на стандарте C99, для разработки параллельных программ, использующих различные вычислительные устройства: графические процессоры, центральные процессоры и другие. При этом параллелизм обеспечивается как на уровне инструкций, так и на уровне данных.
OpenCL является открытым стандартом и поддерживается консорциумом Khronos Group, в который входят крупнейшие IT-компании, включая Intel, NVIDIA и многие другие. Таким образом, программы, написанные на языке OpenCL, могут выполняться практически на всех вычислительных устройствах.
Компиляция приложений, написанных на языке OpenCL
Приложения, написанные на языке OpenCL, могут быть скомпилированы и запущены на различных платформах. Рассмотрим для нашего случая платформу NVIDIA. Для этого необходимо подключить одну из доступных на платформе версий CUDA, используя пакетный модуль Lmod:
|
1 |
$ module add hlit/cuda/*.* |
где *.* — номер версии.
Для компиляции можно воспользоваться различными компиляторами, например, компилятором GCC:
|
1 |
$ gcc helloWorld.c -lOpenCL |
![]()
При компиляции необходимо добавлять опцию -lOpenCL .
После завершения компиляции в текущей директории появится исполняемый файл с именем a.out по умолчанию. Для задания другого имени исполняемому файлу нужно использовать команду:
|
1 |
$ gcc helloWorld.c -o helloWorld.out -lOpenCL |
Тогда исполняемый файл получит название helloWorld.out .
Запуск OpenCL-приложений
Для запуска приложений необходимо воспользоваться следующим скриптом:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#File name script_gpu # Example for one-GPU applications #!/bin/sh # Set the partition where the job will run: #SBATCH -p gpu_k80 # Set the number of GPUs per node #SBATCH --gres=gpu:1 # Set time of work: Avaliable following formats: minutes, minutes:seconds, hours:minutes:seconds, days-hours, days-hours:minutes, days-hours:minutes:seconds; #SBATCH -t 60 # Submit a job for execution: srun ./helloWorld.out # End script |
Приложения запускается командой:
|
1 |
$ sbatch script_gpu |
После запуска задача получит номер:
|
1 |
Submitted batch job XXXXX |
После завершения расчетов в текущей директории будет создан файл slurm-XXXXX.out (где XXXXX — номер задачи), который будет содержать выходные данные программы.
– программный пакет, система компьютерной алгебры, предназначенная для символьных вычислений, хотя имеет ряд средств и для численного решения дифференциальных уравнений и нахождения интегралов. Обладает развитыми графическими средствами. Имеет собственный язык программирования, напоминающий Паскаль.
Подключение переменных окружения пакета
Введите в консоли команду
|
1 |
<span style="color: #bfbfbf;">$ module add Maple/v2020.2-1</span> |
Запуск пакета
– запуск с графическим интерфейсом. Откроется окно программы и вы можете начать работать в нем. Для выхода необходимо выбрать пункт Exit в выпадающем меню.
|
1 |
<span style="color: #bfbfbf;">$ maple</span> |
– запуск в терминальном режиме. В этом случае все команды необходимо вводить в текущей консоли и результаты вычислений будут выводиться в нее же. Для выхода из программы в данном режиме наберите команду
|
1 |
<span style="color: #bfbfbf;">$ quit</span> |
В этом случае расчеты будут проводиться на Вашей ВМ. Для запуска расчетов непосредственно на ресурсах кластера HybriLIT необходимо запускать расчеты через следующий скрипт-файл
|
1 2 3 4 5 6 7 8 9 |
<span style="color: #bfbfbf;">#!/bin/bash #SBATCH -p cpu # задает очередь, в которой будет запущен расчет #SBATCH --job-name=maple # задает имя задачи в очереди (по умолчанию совпадает с названием запускаемого скрипта) #SBATCH --output=maple.out # задает имя выходного файла (по умолчанию slurm-XXX.out) #SBATCH -t 60 #SBATCH -n 1 # задает количество процессоров для расчетов module add Maple/v2020.2-1 maple < maple.mpl # maple.mpl – имя файла с листингом программы </span> |
При добавлении опции
|
1 |
<span style="color: #bfbfbf;">-q</span> |
в выходной файл будет выводиться только результат вычислений, без подсказок ввода и выходных меток. В этом случае последняя команда будет иметь вид
|
1 |
<span style="color: #bfbfbf;">maple —q < maple.mpl</span> |
Информацию по работе и описание основных команд Maple Вы можете посмотреть по ссылкам:
web-страница, pdf-документ.
Mathematica 11.2
– система компьютерной алгебры, широко используемая в научных, инженерных, математических и компьютерных областях. Для системы существуют многочисленные расширения, решающие специализированные классы задач.
Подключение переменных окружения пакета
Введите в консоли команду
|
1 |
$ module add Mathematica/v11.2 |
Запуск пакета
$ mathematica – запуск с графическим интерфейсом. Откроется окно программы, и вы можете начать работать в нем. Для выхода необходимо выбрать пункт Exit в выпадающем меню.
$ math – запуск в терминальном режиме. В этом случае все команды необходимо вводить в текущей консоли и результаты вычислений будут выводиться в нее же. Для выхода из программы в данном режиме наберите команду
$ Quit
В этом случае расчеты будут проводиться на Вашей ВМ. Для запуска расчетов непосредственно на ресурсах кластера HybriLIT необходимо запускать расчеты через следующий скрипт-
|
1 2 3 4 5 6 7 8 |
#!/bin/bash #SBATCH -p cpu # задает очередь, в которой будет запущен расчет #SBATCH --job-name=math # задает имя задачи в очереди (по умолчанию совпадает с названием запускаемого скрипта) #SBATCH --output=math.out # задает имя выходного файла (по умолчанию slurm-XXX.out) #SBATCH -t 60 #SBATCH -n 1 # задает количество процессоров для расчетов module add Mathematica/v11.2 math -run < math.m # math.m – имя файла с листингом программы |
При добавлении опции
|
1 |
-noprompt |
в выходной файл будет выводиться только результат вычислений, без подсказок ввода и выходных меток. В этом случае последняя команда будет иметь вид
|
1 |
math -noprompt -run < math.m |
Документацию по работе в Mathematica и описание основных команд Вы можете посмотреть перейдя по ссылке.
MATLAB r2022b
– пакет прикладных программ для решения задач технических вычислений и одноимённый язык программирования, используемый в этом пакете. Пакет предоставляет пользователю большое количество (несколько сотен) функций для анализа данных, покрывающие практически все области математики.
Подключение переменных окружения пакета
Введите в консоли команду
|
1 |
$ module add MATLAB/r2022b |
Запуск пакета
|
1 |
$ matlab |
– запуск с графическим интерфейсом. Откроется окно программы, и вы можете начать работать в нем. Для выхода необходимо выбрать пункт Exit в выпадающем меню.
|
1 |
$ matlab -nojvm -nodisplay -nosplash |
– запуск программы в режиме терминала. Для выхода из программы в данном режиме наберите команду
|
1 |
$ quit |
В этом случае расчеты будут проводиться на Вашей ВМ. Для запуска расчетов непосредственно на ресурсах кластера HybriLIT необходимо запускать расчеты через следующий скрипт-файл:
|
1 2 3 4 5 6 7 8 9 |
#!/bin/bash #SBATCH -p cpu # задает очередь, в которой будет запущен расчет #SBATCH --mem-per-cpu=4G #задает объем памяти для каждого ядра #SBATCH --job-name=math # задает имя задачи в очереди (по умолчанию совпадает с названием запускаемого скрипта) #SBATCH --output=matlab.out # задает имя выходного файла (по умолчанию slurm-XXX.out) #SBATCH -t 60 #SBATCH -с 1 # задает количество процессоров для расчетов module add MATLAB/r2022b matlab -nodisplay -nosplash < matlab.m # matlab.m – имя файла с листингом программы |
Документацию по работе в Matlab и описание основных команд Вы можете посмотреть перейдя по ссылке.