




About supercomputer
On March 27, 2018, during a session of the Committee of Plenipotentiary Representatives of the Governments of the JINR Member States, a presentation was held for a new supercomputer named in honor of Nikolai Nikolaevich Govorun, whose name has been associated with the development of information technologies at JINR since 1966.
The “Govorun” supercomputer is a joint project of the Bogoliubov Laboratory of Theoretical Physics and Laboratory of Information Technologies, supported by the JINR Directorate.
The project aims to significantly accelerate complex theoretical and experimental research in nuclear physics and condensed matter physics carried out at JINR, including work related to the NICA complex.
The supercomputer is a natural continuation of the HybriLIT heterogeneous platform and will lead to a substantial increase in the performance of both the CPU and GPU components of the platform. The upgraded computing cluster will enable resource-intensive, massively parallel calculations in lattice quantum chromodynamics to study the properties of hadronic matter at high energy density and baryon charge, and in the presence of ultra-strong electromagnetic fields. It will significantly improve the speed and quality of simulations of relativistic heavy-ion collisions, open new opportunities for the study of strongly correlated systems in the field of new materials physics, and support the development and adaptation of software for the NICA mega-project to new computing architectures from major HPC market leaders such as Intel and NVIDIA. It will also help create a software-hardware environment based on HPC and train IT specialists in all the necessary areas.
The CPU component was expanded using a specialized engineering infrastructure for HPC based on direct liquid cooling technology, implemented by the Russian company RSC Technologies JSC. This company is a market leader in Russia in the field of HPC solutions using liquid cooling, based on a number of proprietary technologies that allow for the creation of ultra-compact and energy-efficient HPC systems with high computing density.
The GPU component was expanded using next-generation computing servers with NVIDIA Volta GPUs. The supply of equipment and commissioning work for the GPU-based cluster was carried out by the systems integrator IBS Platformix.
Technical Specifications
See technical specifications on the website of the RSC Group of Companies
2.2 PFLOPS total peak performance at double precision
10,6 PB of data storage capacity

CPU component
The company RSC Technologies JSC has developed an updated ultra-dense, scalable, and energy-efficient cluster solution, which is a set of components for building modern computing systems of various scales, featuring 100% liquid cooling using “hot water” mode.
The system includes high-performance compute nodes based on Intel Xeon Phi and Intel Skylake SP (Scalable Processor) CPUs, combined with a high-speed Intel Omni-Path switch, also cooled using “hot water” liquid coolingtechnology.
800 TFLOPS peak performance at double precision
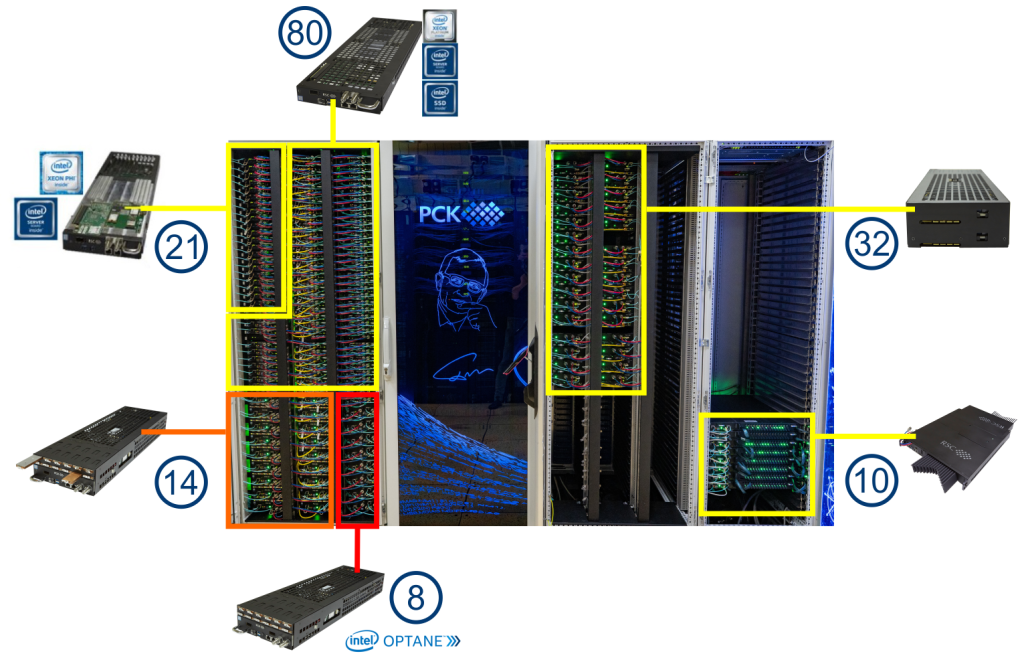
Specifications
- Intel® Xeon Phi™ 7190 processors (72 cores)
- Intel® Server Board S7200AP
- Intel® SSD DC S3520 (SATA, M.2)
96GB DDR4 2400 GHz RAM - Intel® Omni-Path 100 Gb/s adapter
- Intel® Xeon® Platinum 8268 processors (24 cores)
- Intel® Server Board S2600BP
- Intel® SSD DC S4510(SATA, M.2),
2x Intel® SSD DC P4511 (NVMe, M.2) 2TB - 192GB DDR4 2933 GHz RAM
- Intel® Omni-Path 100 Gb/s adapter
View the technical specifications of the RSC Tornado TDN511 blade server
- Intel Xeon Platinum 8280 processors (28 cores)
- Intel® Server Board S2600BP
- Intel® SSD DC S4510(SATA, M.2),
2x Intel® SSD DC P4511 (NVMe, M.2) 2TB / 4x Intel® (PMem) 450 GB - 192GB DDR4 2933 GHz RAM
- Intel® Omni-Path 100 Gb/s adapter
View the technical specifications of the RSC Tornado TDN511S blade server
- 2x Intel Xeon Platinum 8368Q processors (38 cores)
- Gigabyte Server Board MH62-HD0-R5
- Gigabyte PCIe SSD (NVMe) 256 GB
- 4x Intel® PCIe DC P451 (NVMe) 4 TB
- 2 TB DDR4 3200 GHz RAM
- 2x Intel® Omni-Path 100 Gb/s adapter
View the technical specifications of the RSC Tornado TDN711 blade server
GPU component
1.4 PFLOPS peak performance with double precision
58 PFLOPS peak performance with half precision
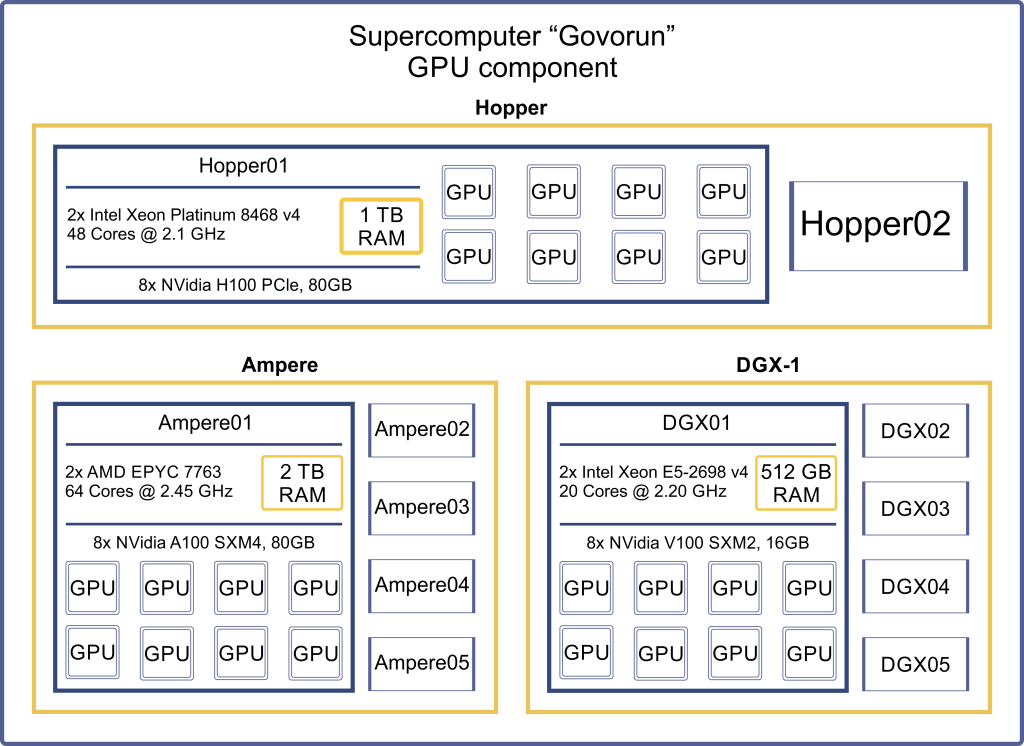
The “Govorun” supercomputer includes 2 RSC Exastream AI servers, 5 Niagara R4206SG servers, and 5 NVIDIA DGX-1 servers.
RSC Exastream AI
The RSC Exastream AI server is a modern modular hardware-software platform designed for high-performance computing aimed at solving scientific and engineering problems using artificial intelligence technologies. This platform was specifically developed for the Govorun supercomputer, taking into account its architectural and hardware features, including the use of liquid cooling for server components. The Govorun supercomputer is equipped with 2 RSC Exastream AI servers, each containing 8 NVIDIA H100 GPUs.
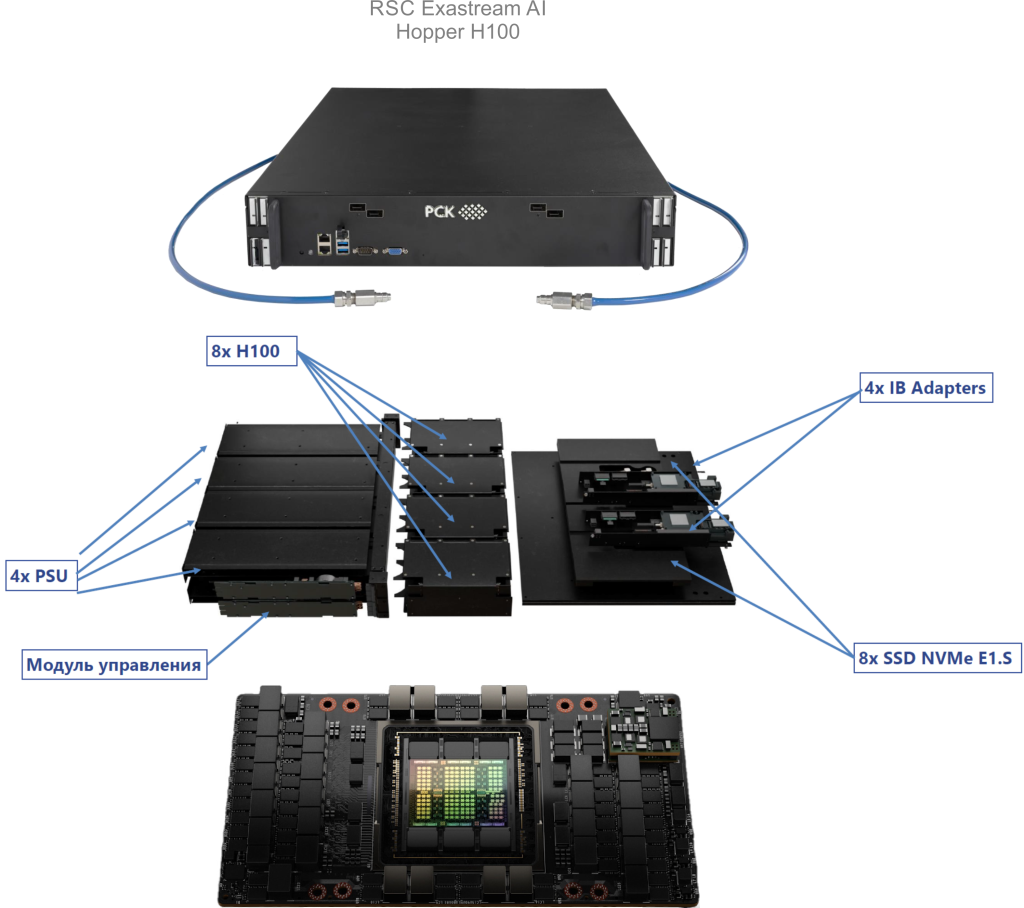
Technical specifications of the RSC Exastream AI server and the Hopper H100 GPU accelerator:
RSC Exastream AI:
- CPU: 2x Intel Xeon Platinum 8468, 48 Cores @ 2.10 GHz
- RAM: 1 TB DDR5
- NET: 2x Nvidia Mellanox 200 Gbit/sec
- GPU: 8x NVidia H100 SXM5, 80 GB
Hopper H100:
CUDA Cores: 14592
Tensor Cores: 456 (Gen.4)
TMUs: 456
ROPs: 24
SM: 114
L1 cache: 256 KB (per SM)
L2 cache: 50 MB
FP16: 102.4 TFLOPS
FP32: 51.2 TFLOPS
FP64: 25.6 TFLOPS
Deep Learning: 1513 TFLOPS
View the Nvidia Hopper H100 graphics accelerator technical description
Niagara R4206SG
The Niagara R4206SG server is a system designed for use in data centers to solve tasks in the fields of artificial intelligence, data analytics, and high-performance computing.
The Govorun supercomputer is equipped with and configured to use 5 servers with NVIDIA A100 GPUs, based on the Niagara solution model R4206SG (Supermicro AS-4124GO-NART+).
The R4206SG server supports up to 256 threads (the number of CPU cores considering hyperthreading) and has 2 TB of RAM. Each server is equipped with 8 NVIDIA A100 GPUs, featuring:
• 80 GB of GPU memory
• 6,192 CUDA cores
• 432 texture mapping units (TMUs)
• 160 raster operation units (ROPs)

Technical specifications of the Niagara R4206SG server and the Ampere A100 GPU accelerator:
- CPU: 2x AMD EPYC 7763, 64 Cores @ 2.45 GH
- RAM: 2 TB
- NET: 2x Nvidia Mellanox 100 Gbit/sec,
2x Supermicro AIOM 100 Gbit/sec (ethernet) - GPU: 8x NVidia A100 SXM4, 80 GB
- CUDA Cores: 6912
- Tensor Cores: 432 (Gen.3)
- TMUs: 320
- ROPs: 160
- SM: 108
- L1 cache: 192 KB (per SM)
- L2 cache: 40 MB
- FP16: 77.97 TFLOPS
- FP32: 19.49 TFLOPS
- FP64: 9.746 TFLOPS
- Deep Learning: 624 TFLOPS
NVidia DGX-1
The NVIDIA DGX-1 hardware-software platform is the world’s first system specifically designed for deep learning tasks and accelerated data analytics in the field of artificial intelligence.
This system includes 8 NVIDIA V100 GPUs, based on the Volta architecture.
The DGX-1 platform enables data processing and analysis with performance comparable to 250 x86 servers

Technical specifications of the DGX-1 server and the Volta V100 GPU accelerator:
- CPU: 2x Intel Xeon E5-2698 v4, 20 Cores @ 2.20 GHz
- RAM: 512 GB
- NET: 2x Mellanox InfiniBand 100 Gbit/sec,
1x Mellanox InfiniBand 100 Gbit/sec (ethernet),
1x Intel Omni-Path 100 Gbit/sec
- GPU: 8x NVidia V100 SXM2, 16 GB
- CUDA Cores: 5120
- Tensor Cores: 640 (Gen.1)
- TMUs: 320
- ROPs: 128
- SM: 80
- L1 cache: 128 KB (per SM)
- L2 cache: 6 MB
- FP16: 31.33 TFLOPS
- FP32: 15.67 TFLOPS
- FP64: 7.834 TFLOPS
- Deep Learning: 125.92 TFLOPS
View the technical specifications of the Nvidia Volta V100 GPU accelerator
Data storage systems

Working with Data on the Govorun Supercomputer
The Govorun supercomputer includes the RSC Storage on-Demand networked storage system, which is a unified, centrally managed system with several levels of data storage — very hot data, hot data, and warm data.
- The very hot data storage system is built on four RSC Tornado TDN511S blade servers. Each server is equipped with 12 high-speed, low-latency Intel® Optane™ SSD DC P4801X 375GB M.2 Series solid-state drives using Intel® Memory Drive Technology (IMDT), providing 4.2 TB of very hot data storage per server.
- The hot and warm data storage system consists of a static storage system with the parallel Lustre file system, based on 14 RSC Tornado TDN511S blade servers, and a dynamic RSC Storage on-Demand system with 84 RSC Tornado TDN511 blade servers supporting the Lustre parallel file system.
For fast access to Lustre file system metadata without latency, low-latency Intel® Optane™ SSD DC P4801X 375GB M.2 Series solid-state drives are used. Intel® SSD DC P4511 (NVMe, M.2) solid-state drives are used to store hot data in Lustre.
The network infrastructure module includes communication and transport networks, management and monitoring networks, and job management networks.
The NVIDIA DGX-1 servers are interconnected by a communication and transport network based on InfiniBand 100 Gbps technology, and their connection to the CPU module is done via Intel OmniPath 100 Gbps.
The communication and transport network of the CPU module uses Intel OmniPath 100 Gbps technology and is built on a fat-tree topology using 48-port Intel OmniPath Edge 100 Series switches with full liquid cooling.
An important part of the Govorun supercomputer architecture is the RSC BazIS supercomputer management software. RSC BazIS runs CentOS Linux version 7.8 on all compute nodes (CN) and performs the following functions:
- Monitors compute nodes with emergency shutdown functionality in case of critical faults (such as overheating of compute nodes);
- Collects performance metrics of communication and transport network components;
- Collects performance metrics of compute nodes — CPU and RAM load;
- Stores monitored metrics with the ability to view statistics over a specified time interval (at least one year);
- Collects integrated health indicators of compute nodes and displays them on a geometric visualization of the compute rack;
- Displays leak detection system status based on humidity sensor data on compute nodes, also visualized on the compute rack geometry;
- Displays resource usage efficiency via the SLURM scheduler to cluster users for specific tasks, shown as average CPU load (%) allocated by the user;
- Displays availability of compute nodes via the compute network and management network on the geometric visualization of the compute rack.